









だいぶ前にPowerShellでPDFファイルを読み込む方法を記事にしていますが、今回はPythonでPDFファイルを読み込む方法となります
使用するモジュールは【pypdf】となります。調べたら執筆時点(2025年上期中)ではこのモジュールがいいらしいです
-
 - ナストンのまとめ")
-
PowerShellでファイル読み込み(PDF) - ナストンのまとめ
PDFファイルを読み込んでみる 読み込むファイルの種類 今回、紹介するファイル読み込みは以下の拡張子が対象です・PDFフ ...
関連記事へ
 - ナストンのまとめ")
| 名称 | バージョン |
|---|---|
| Python | 3.12 |
| pypdf | 5.2.0 |
| Pillow | 11.1.0 |
PDFファイルのテキスト情報を読み込んでみる
読み込むPDFファイルは以下のサイトのものを使用して確認しました
-
-
https://www.env.go.jp/content/900473374.pdf
対象PDFファイルへ

まず初めに対象PDFファイルのページ数を取得し、その後テキスト情報を取得しています。取得する際に余分な空白は削除するようにしています。
from pypdf import PdfReader
# PDFファイルの読み込み
reader = PdfReader("900473374.pdf")
# ページ数の取得
number_of_pages = len(reader.pages)
print(number_of_pages)
# ページのテキストを取得
for i, page in enumerate(reader.pages):
print(f"Page {i + 1} Text:")
print(page.extract_text())
# 縦方向の余分な空白を削除
print(page.extract_text(layout_mode_space_vertically=False))実際に実行すると以下のように出力されます
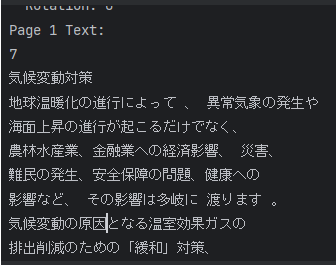
extract_text関数で使用できる引数については以下の公式ドキュメントを参考にしてみてください(英語のサイトとなります)
-
-
Extract Text from a PDF — pypdf 6.9.2 documentation
公式サイトへ

PDFファイルのメタデータを取得する
PDFファイルの様々なメタデータを取得します
# PDFのメタデータの取得
metadata = reader.metadata
print("PDF Metadata:")
for key, value in metadata.items():
print(f"{key}: {value}")
# 各ページのメタデータの取得
for i, page in enumerate(reader.pages):
print(f"Page {i + 1} Metadata:")
print(f" Size: {page.mediabox}")
print(f" Rotation: {page.rotation}")実行すると以下のような情報が取得できます
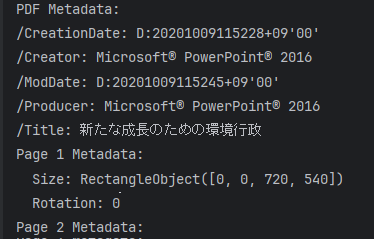
画像情報を取得してJPEGファイルとして出力する
画像データをファイルとして出力するのに『Pillow』というモジュールを使用しています
for i,page in enumerate(reader.pages):
print(f"Page {i + 1} Image:")
for j, image_file_object in enumerate(page.images):
# 画像のバイナリデータを取得
image_data = image_file_object.data
# バイナリデータをPillowのImageオブジェクトに変換
image = Image.open(io.BytesIO(image_data))
# 画像のモードがRGBAの場合はRGBに変換
if image.mode == 'RGBA':
image = image.convert('RGB')
# 画像をJPEG形式で保存
image.save(f"page_{i + 1}_image_{j + 1}.jpg", "JPEG")以下のように画像データを出力することができました

最後に
今回はテキスト情報を取得したり、メタデータ取得、画像データ出力をしましたが他にもPDFファイルの統合などもできるようなので試してみてください
会社紹介
私が所属しているアドバンスド・ソリューション株式会社(以下、ADS)は一緒に働く仲間を募集しています
会社概要
「技術」×「知恵」=顧客課題の解決・新しい価値の創造
この方程式の実現はADSが大切にしている考えで、技術を磨き続けるgeekさと、顧客を思うloveがあってこそ実現できる世界観だと思っています
この『love & geek』の精神さえあれば、得意不得意はno problem!
技術はピカイチだけど顧客折衝はちょっと苦手。OKです。技術はまだ未熟だけど顧客と知恵を出し合って要件定義するのは大好き。OKです
凸凹な社員の集まり、色んなカラーや柄の個性が集まっているからこそ、常に新しいソリューションが生まれています
ミッション
私たちは、テクノロジーを活用し、業務や事業の生産性向上と企業進化を支援します
-
-
アドバンスド・ソリューション株式会社|ADS Co., Ltd.
Microsoft 365/SharePoint/Power Platform/Azure による DX コンサル・シス ...
サイトへ移動

